
赵浩翰
Sunday, July 28, 2024 | 8 minutes
第三章 线性神经网络
1. 线性回归
1.1 线性回归的基本元素
1.1.1 线性模型
线性回归,假设自变量 $\bold{x}$ 和因变量 $y$ 之间为线性关系,其中可能包含噪声,但噪声是比较正常的,如噪声服从正态分布。
给定一个样本 $\bold{x}\in\mathbb{R}^{d}$,即具有 $d$ 个特征,将所有系数记为 $\bold{w}\in\mathbb{R}^{d}$,线性回归的基本形式为: $$ \hat{y} = \bold{w}^{T}\bold{x} + b $$
矩阵形式下,$\bold{X}\in\mathbb{R}^{n\times d}$ 为所有样本的特征,此时线性回归表示为: $$ \hat{\bold{y}} = \bold{Xw} + b $$
给定训练数据集 $\bold{X}$ 和对应标签 $\bold{y}$,线性回归的目标就是找到一组权重向量 $\bold{w}$ 和偏置 $b$,使得所有样本的预测误差尽可能小。
1.1.2 损失函数
损失函数,用以度量上面提到的 “预测误差”,通常选择一个非负数作为损失,且该损失越小越好。回归问题中,最常用的损失函数为 平方误差,当样本 $i$ 的预测值为 $\hat{y}^{(i)}$,相应真实标签为 $y^{(i)}$ 时,平方误差定义为: $$ l^{(i)}(\bold{w}, b) = \frac{1}{2}\left(\hat{y}^{(i)} - y^{(i)} \right)^{2} $$
$\frac{1}{2}$ 是为了损失函数求导时常数系数为 1,不会有本质差别。
那么,为了度量模型在整个训练集上的表现,就需要计算在整个训练集 $n$ 个样本上的损失均值 (等价于求和): $$ L(\bold{w}, b) = \frac{1}{n}\sum_{i=1}^{n}l^{(i)}(\bold{w},b) = \frac{1}{n}\sum_{i=1}^{n}\frac{1}{2}\left(\bold{w}^{T}\bold{x}^{(i)} + b - y^{(i)} \right)^{2} $$
此时,模型训练的目标就是寻找一组参数 $(\bold{w}^{*},b^{*})$,以最小化所有训练样本上的总损失,即: $$ \bold{w}^{*},b^{*} = \argmin_{\bold{w},b}L(\bold{w},b) $$
1.1.3 解析解
线性回归可以求出解析解,将偏置 $b$ 合并到权重 $\bold{w}$ 中,最小二乘法,即可得到: $$ \bold{w}^{*} = (\bold{X}^{T}\bold{X})^{-1}\bold{X}^{T}\bold{y} $$
1.1.4 随机梯度下降
对于其他更复杂的模型,可能不存在解析解,那么就需要使用一些数值优化方法,以求得数值解。深度学习中常用 梯度下降法 (Gradient Decent)。梯度下降通过计算损失函数关于模型参数的导数 (此处也可称为梯度),来更新参数。在实际中遍历整个数据集可能非常缓慢,所以我们通常每次随机抽取一小批样本计算,这种方法称为 小批量随机梯度下降 (minibatch stochastic gradient decent)。
每次迭代,随机抽取一个小批量 $B$,计算该批次的损失均值关于参数的导数,乘以一个预先确定的正数 $\eta$ (学习率),并从当前参数中减去,以数学公式表示如下: $$ (\bold{w}, b)\leftarrow(\bold{w}, b) - \frac{\eta}{|B|}\sum_{i\in B}\partial_{\bold{w}, b}l^{(i)}(\bold{w}, b) $$
总结:算法步骤如下:
- 初始化模型参数,如随机初始化
- 从数据集抽取小批量样本且在负梯度方向上更新参数,并不断迭代这个步骤
对于平方损失函数,我们有: $$ \begin{align*} \bold{w}&\leftarrow \bold{w} - \frac{\eta}{|B|}\sum_{i\in B}\partial_{\bold{w}}l^{(i)}(\bold{w}, b) = \bold{w} - \frac{\eta}{|B|}\sum_{i\in B}\bold{x}^{(i)}(\bold{w}^{T}\bold{x}^{(i)} + b - y^{(i)}) \cr b&\leftarrow b - \frac{\eta}{|B|}\sum_{i\in B}\partial_{b}l^{(i)}(\bold{w}, b) = b - \frac{\eta}{|B|}\sum_{i\in B}(\bold{w}^{T}\bold{x}^{(i)} + b - y^{(i)}) \end{align*} $$
批量大小 $B$ (batch size) 和学习率 $\eta$ (learning rate) 通常是预先确定的,此类参数称为超参数 (hyperparameter),调参 (hyperparameter tuning) 就是选择超参数的过程。这个选择过程通常是根据训练迭代的结果来调整的,训练迭代结果一般在独立的 验证数据集 (validation dataset) 上得到。
我们的最终目标是:通过训练集的训练和验证集上参数的选择,找到一组具有比较良好泛化 (generalization) 能力的模型参数的估计值 $\hat{\bold{w}},\hat{b}$,使其在没有见过的样本上也具有较小的损失。
1.2 正态分布与平方损失
线性回归中假设观测中包含噪声,而该噪声服从正态分布,这也是为什么线性回归可以使用均方误差的原因。噪声正态分布如下式: $$ y = \bold{w}^{T}\bold{x}^{(i)} + b + \epsilon, \epsilon\sim N(0, \sigma^{2}) $$
下面证明为什么可以使用均方损失。给定 $\bold{x}$ 时 观测到 $y$ 的似然 (likelihood) 为: $$ P(y|\bold{x}) = \frac{1}{\sqrt{2\pi\sigma^{2}}}exp\left(-\frac{1}{2\sigma^{2}}(y - \bold{w}^{T}\bold{x}^{(i)} - b)^{2} \right) $$
利用极大似然估计,参数 $\bold{w}, b$ 的最优值是使整个数据集的似然最大的值,即: $$ P(\bold{y}|\bold{X}) = \prod_{i=1}^{n}p(y^{(i)}|\bold{x}^{(i)}) $$
极大似然估计法得到的估计量称为极大似然估计量,取对数,再取负,则可以将目标变为最小化负对数似然 $-\log P(\bold{y}|\bold{X})$,即: $$ -\log P(\bold{y}|\bold{X}) = \sum_{i=1}^{n}\frac{1}{2}\log(2\pi\sigma^{2}) + \frac{1}{2\sigma^{2}}(y^{(i)} - \bold{w}^{T}\bold{x}^{(i)} - b)^{2} $$
在正态噪声的假设下,再假设 $\sigma$ 为常数,上式即与均方误差等价。
2. 从零开始实现线性回归
- 生成数据集
def synthetic_data(w, b, num_examples):
"""生成 y = Xw + b + 噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
- 读取数据集,随机取一个小批量
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 样本随机读取,没有特定的顺序
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
- 初始化模型参数,正态分布初始化
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
- 定义模型
def linreg(X, w, b):
"""线性回归模型"""
return torch.matmul(X, w) + b
- 定义损失函数
def squared_loss(y_hat, y):
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
- 定义优化算法
def sgd(params, lr, batch_size):
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
- 训练
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X 和 y 的小批量损失
# 因为 l 形状是 (batch_size,1),而不是一个标量。l 中的所有元素被加到一起,
# 并以此计算关于 [w, b] 的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
3. 线性回归的简洁实现
- 生成数据集
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
- 读取数据集
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个 PyTorch 数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
- 定义模型
net是一个Sequential类的实例。Sequential类将多个层串联在一起。 当给定输入数据时,Sequential实例将数据传入到第一层, 然后将第一层的输出作为第二层的输入,以此类推。
# nn 是神经网络的缩写
from torch import nn
net = nn.Sequential(nn.Linear(2, 1))
- 初始化模型参数
在使用
net之前,需要初始化模型参数。深度学习框架通常有预定义的方法来初始化参数,在这里,我们指定每个权重参数应该从均值为 0、标准差为 0.01 的正态分布中随机采样,偏置参数将初始化为零。 通过net[0]选择网络中的第一个图层,然后使用weight.data和bias.data方法访问参数,使用替换方法normal_和fill_来重写参数值。
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
- 定义损失函数
计算均方误差使用的是
MSELoss类,也称为平方 $L_{2}$ 范数。默认情况下,它返回所有样本损失的平均值。
loss = nn.MSELoss()
- 定义优化算法
PyTorch在optim模块中实现了该算法的许多变种。实例化一个SGD实例,指定优化的参数 (可通过net.parameters()从我们的模型中获得) 以及优化算法所需的超参数。小批量随机梯度下降只需要设置lr值,这里设置为 0.03。
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
- 训练
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)线性模型
print(f'epoch {epoch + 1}, loss {l:f}')
4. Softmax 回归
前述内容是应用于回归预测的线性模型,除此之外,它也可以用于分类问题。
4.1 分类问题
在样本特征方面,与回归类似,每个样本有一个特征向量。而在预测标签方面,如预测猫、狗、鸡,一个直接的想法是选择 ${1,2,3}$,但这会为类别赋予“顺序”信息,在类别间有一定自然顺序时,这样做是可行的,如 ${婴儿,儿童,青年,老年}$,但该类问题亦可以转化为回归问题。因此,在预测标签方面,一般使用 独热编码 (one-hot encoding)。独热编码是一个具有与类别数相同个数分量的向量,类别对应的分量设为 1,其余为 0。如猫、狗、鸡可以设置为 ${(1,0,0),(0,1,0),(0,0,1)}$。
4.2 网络架构
为了估计所有可能类别的条件概率,就需要一个多输出的模型,每个类别对应一个输出,即设置与类别个数相同的仿射函数。假设如上的例子中有 4 个特征,那么我们便需要 3 个 4 元回归方程,共 12 个参数、4 各偏置。如下我们为每个输入计算 3 个未规范化的预测 (logit) $o_{1},o_{2},o_{3}$: $$ \begin{align*} o_{1} &= x_{1}w_{11} + x_{2}w_{12} + x_{3}w_{13} + x_{4}w_{14} + b_{1} \cr o_{2} &= x_{1}w_{21} + x_{2}w_{22} + x_{3}w_{23} + x_{4}w_{24} + b_{2} \cr o_{3} &= x_{1}w_{31} + x_{2}w_{32} + x_{3}w_{33} + x_{4}w_{34} + b_{3} \end{align*} $$
仍将模型表达为矩阵形式,则有 $\bold{o=Wx+b}, W\in\mathbb{R}^{3\times4}, x\in\mathbb{R}^{4}, b\in\mathbb{R}^{3}$。
只使用一个神经层进行 softmax 回归时,输出层同时也是全连接层,其参数开销为 $O(dq)$,$d$ 是输入维度,$q$ 是输出维度,在实践中可能非常大,但有一定的方式可以把这个开销降低至 $O(dq/n)$,$n$ 为超参数,可以灵活设置,以在参数节省和模型有效性间合理权衡。
4.3 softmax 运算
上述网络的输出是未经规范化的预测:我们没有限制它们的和为 1,也没有限制它们的值不能为负,这违背了概率公理,因此,若要将输出视为概率,我们需要保证输出非负且和为 1,且需要一个目标函数,以激励模型精准地估计概率,该属性称之为 校准 (calibration)。
softmax 函数正是我们所需要的,其计算公式如下: $$ \hat{\bold{y}} = softmax(\bold{o}), \hat{y}_{j}=\frac{\exp (o_j)}{\sum_k \exp (o_k)} $$
该函数不会改变原有的大小次序,且可导,我们认可通过下式选择最有可能的类别: $$ \argmax_{j}\hat{y}_{j} = \argmax_jo_j $$
4.4 批量样本的向量化
将上述内容结合批量,输入数据为 $\bold{X}\in\mathbb{R}^{n\times d}$,权重为 $\bold{W}\in\mathbb{R}^{d\times q}$,偏置为 $\bold{b}\in\mathbb{1\times q}$,则 softmax 可以写为: $$ \begin{align*} \bold{O}&=\bold{XW+b} \cr \hat{\bold{Y}} &= softmax(\bold{O}) \end{align*} $$
其中,softmax 函数按行运算。
4.5 损失函数
softmax 函数的输出给出了一个向量 $\hat{\bold{y}}$,可以理解为任意给定输入 $\bold{x}$ 时每个类别的条件概率,设整个数据集 ${\bold{X,Y}}$ 有 $n$ 个样本,索引 $i$ 的特征向量和独热标签向量分别为:$\bold{x}^{(i)},\bold{y}^{(i)}$,比较估计值和真实值即有: $$ P(\bold{Y}|\bold{X})=\prod_{i=1}^{n}P(\bold{y}^{(i)}|\bold{x}^{(i)}) $$
进行极大似然估计,最大化 $P(\bold{Y}|\bold{X})$,即最小化负对数似然: $$ -\log P(\bold{Y}|\bold{X}) = \sum_{i=1}^{n}-\log P(\bold{y}^{(i)}|\bold{x}^{(i)}) = \sum_{i=1^{n}}l(\bold{y}^{(i)}, \hat{\bold{y}}^{(i)}) $$
其中,对于任意标签 $\bold{y}$ 和模型预测 $\hat{\bold{y}}^{(i)}$,损失函数为: $$ l(\bold{y}^{(i)}, \hat{\bold{y}}^{(i)})=-\sum_{j=1}^{q}y_{i}\log\hat{y}_{j} $$
上式通常称为 交叉熵损失 (cross-entropy loss)。注意,$\bold{y}$ 是一个长度为 $q$ 的独热编码向量,即只有一个分量为 1,则该式仅有一项,且由于概率值不大于 1,因此取对数后不大于 0,则该损失函数永远是一个非负值,预测的概率越准确,该值越接近于 0。
将 $\hat{y}$ 的 softmax 计算代入上式,则有: $$ \begin{align*} l(\bold{y}^{(i)}, \hat{\bold{y}}^{(i)}) &= -\sum_{j=1}^{q}y_j\log\frac{\exp (o_j)}{\sum_{k=1}^{q}\exp (o_k)} \cr &= \sum_{j=1}^{q}y_{j}\log\sum_{k=1}^{q}\exp(o_k) - \sum_{j=1}^{q}y_jo_j \cr &= \log\sum_{k=1}^{q}\exp(o_k) - \sum_{j=1}^{q}y_jo_j \end{align*} $$
对任意为规范化的预测 $o_j$ 求导可得: $$ \partial_{o_{j}}l(\bold{y}^{(i)}, \hat{\bold{y}}^{(i)})=\frac{\exp(o_j)}{\sum_{k=1}^{q}\exp (o_k)} - y_j = softmax(\bold{o})_j - y_j $$
即:导数是我们 softmax 函数分配的概率与真实独热标签表示的概率之间的差。
最后,我们的模型对任意样本的特征输出每个类别的概率,一般取其中预测概率最高的类别作为输出类别。
5. Fashion-MNIST 数据集
Fashion-MNIST 数据集包含 10 个类别的图像,高度和宽度为 28 像素,灰度图像,通道数为 1。训练集和测试集分别包括 60000 和 10000 张图像。首先读取数据集,并定义绘图和标签转换函数。
%matplotlib inline
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
d2l.use_svg_display()
# 通过 ToTensor 实例将图像数据从 PIL 类型变换成 32 位浮点数格式,
# 并除以 255 使得所有像素的数值均在 0~1 之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
def get_fashion_mnist_labels(labels):
"""返回 Fashion-MNIST 数据集的文本标签"""
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):
"""绘制图像列表"""
figsize = (num_cols * scale, num_rows * scale)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL 图片
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes
def get_dataloader_workers():
"""使用 4 个进程来读取数据"""
return 4
def load_data_fashion_mnist(batch_size, resize=None):
"""下载 Fashion-MNIST 数据集,然后将其加载到内存中"""
# 通过 ToTensor 实例将图像数据从 PIL 类型变换成 32 位浮点数格式
trans = [transforms.ToTensor()]
# 使用 resize 将图像调整到另一种形状
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
# 下载数据集
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
# 返回内置数据迭代器
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
for X, y in train_iter:
print(X.shape, X.dtype, y.shape, y.dtype)
break
6. softmax 回归从零实现
首先,加载数据并初始化模型参数:
import torch
from IPython import display
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs = 784 # 28*28 的图像视为一维向量
num_outputs = 10 # 对应 10 个类别
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True) # 784*10
b = torch.zeros(num_outputs, requires_grad=True) # 1*10
定义模型、softmax 函数、损失函数、分类精度、评估函数:
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition
def net(X):
return softmax(torch.matmul(X.reshape(-1, W.shape[0]), W) + b)
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
def accuracy(y_hat, y):
"""计算预测正确的数量"""
if (len(y_hat.shape) > 1) and (y_hat.shape[1] > 1):
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
def evaluate_accuracy(net, data_iter):
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = d2l.Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
定义训练、预测过程:
def train_epoch_ch3(net, train_iter, loss, updater):
"""训练模型一个迭代周期(定义见第 3 章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用 PyTorch 内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
"""训练模型(定义见第 3 章)"""
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
def predict_ch3(net, test_iter, n=6):
"""预测标签(定义见第 3 章)"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
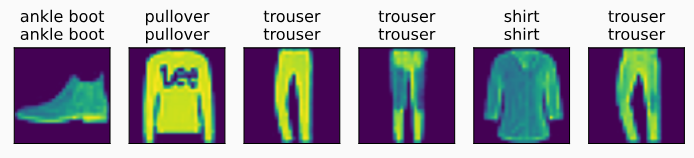
predict_ch3(net, test_iter)
预测结果如下所示:
7. softmax 回归的简洁实现
import torch
from torch import nn
from d2l import torch as d2l
# 加载数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 定义网络
# PyTorch 不会隐式地调整输入的形状。因此,我们在线性层前定义了展平层(flatten),来调整网络输入的形状
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
# 损失函数
# PyTorch 为交叉熵损失函数传递未规范化的预测,在函数中再计算 softmax 及其对数
loss = nn.CrossEntropyLoss(reduction='none')
# 优化器
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
# 训练
num_epochs = 10
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
7.1 重新审视 softmax 的实现
softmax 函数中需要取 $\exp$,在遇到较大的 $o_k$ 时,可能会导致数值 上溢,最终结果可能出现 0、inf 或 nan 值。
我们可以通过为所有 $o_k$ 减去 $\max(o_k)$ 来解决上溢问题,因为: $$ \begin{align*} \hat{y}_j &= \frac{\exp(o_j-\max(o_k))\exp(\max(o_k))}{\sum_k\exp(o_k-\max(o_k))\exp(\max(o_k))} \cr &= \frac{\exp(o_j-\max(o_k))}{\sum_k\exp(o_k-\max(o_k))} \end{align*} $$
但在上述减法和规范化步骤后,可能有一些 $o_j-\max(o_k)$ 出现较大负值,取指数后的值非常接近 0,即 下溢,则最后取对数时得到 -inf 值。
但幸运的是,尽管我们要计算指数函数,但我们最终在计算交叉熵损失时会取它们的对数。 通过将 softmax 和交叉熵结合在一起,可以避免反向传播过程中可能会困扰我们的数值稳定性问题。 如下面的等式所示,我们避免计算 $\exp(o_j-\max(o_k))$,直接使用 $o_j-\max(o_k)$: $$ \begin{align*} \log(\hat{y}_j) &= \log\left(\frac{\exp(o_j-\max(o_k))}{\sum_k\exp(o_k-\max(o_k))}\right) \cr &= \log(\exp(o_j-\max(o_k))) - \log\left(\sum_k\exp(o_k-\max(o_k))\right) \cr &= o_j-\max(o_k) - \log\left(\sum_k\exp(o_k-\max(o_k))\right) \end{align*} $$
PyTorch 没有将 softmax 概率传递到损失函数中, 而是在交叉熵损失函数中传递未规范化的预测,在函数中再计算 softmax 及其对数, 这是一种类似 “LogSumExp 技巧” 的聪明方式。